The increase in recent years in the sophistication, power, and user-friendliness of spreadsheets such as Microsoft Excel has meant that more decision makers are building their own spreadsheet models to help them in their decision making. These models however are only as good as two things. Firstly, the data that goes into the model, and secondly, the logic of the relationships built into the model. Inaccurate input data values or faulty logic can only produce bad results, especially if the inaccurate data values are the key or critical variables (Beaman, Ratnatunga, Krueger, and Mudalige, 2002). Obviously, more care should be taken when estimating an input variable to which the output is highly sensitive and conversely, less time and care taken in estimating an input variable to which the output is less sensitive (Beaman et al., 2002). But, how model builder can identify which variables are key or critical? Performing sensitivity analysis is the answer to this question.
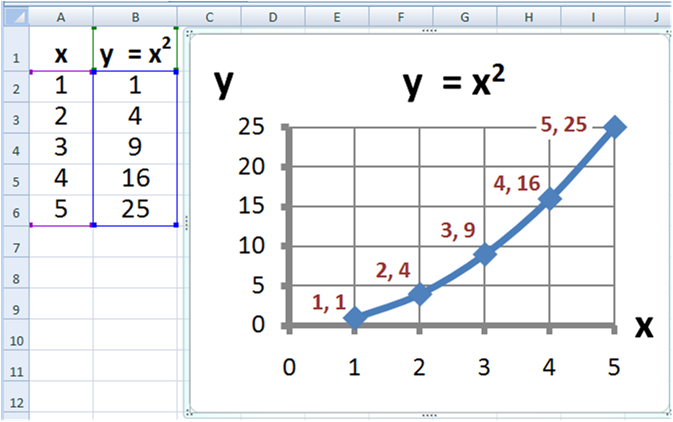 English: Plot of y=x 2 made in Microsoft Excel. Al...
English: Plot of y=x 2 made in Microsoft Excel. Al...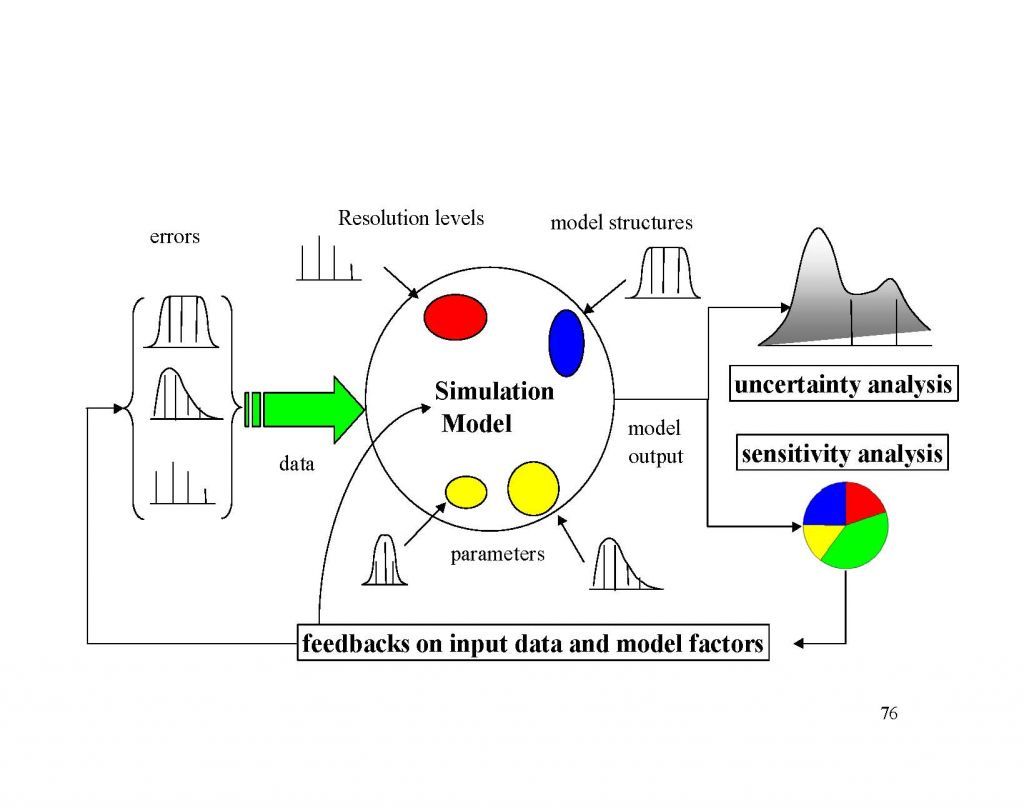 Scheme for sensitivity analysis
Scheme for sensitivity analysis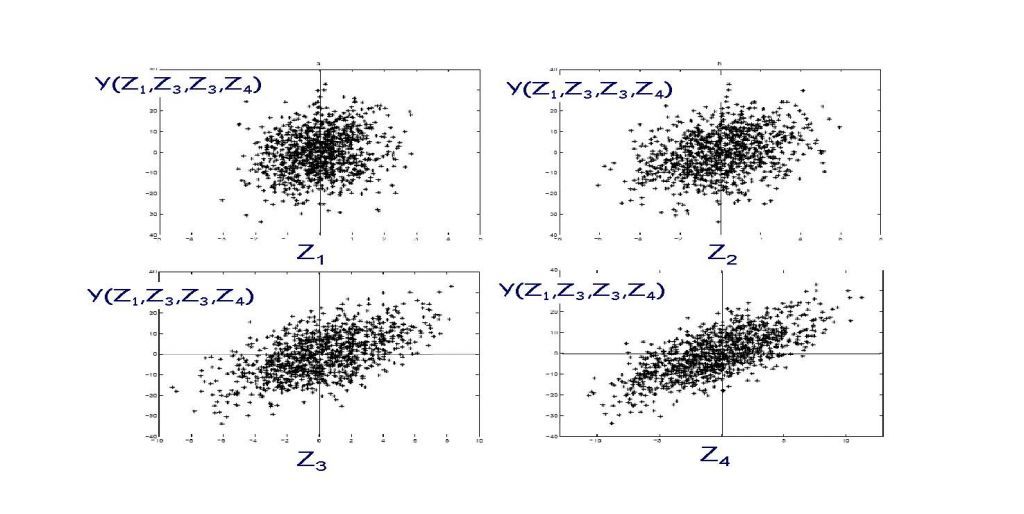 Sampling-based sensitivity analysis by scatterplot...
Sampling-based sensitivity analysis by scatterplot...Sensitivity analysis enables the model builder to identify the key variables. In other words to identify those input variables to which the output is most sensitive.
Sensitivity analysis itself involves determining the impact on a model's result of a change made to only one input variable, while holding all other variables constant. Small changes to this input variable may result in dramatic changes to the results. In this case, the results are said to exhibit high sensitivity to this input variable. Alternatively, a change in this input variable may produce little overall change in the results; thus, low sensitivity (Beaman et al., 2002). In short, sensitivity analysis determines which input distributions have the biggest impact on the outputs (Broadleaf Capital International, Accessed 21 April 2004).
Furthermore, sensitivity analysis allows the decision maker to determine which input variables have the most impact on the...
No picture and no reference list?
there are no any pictures for "Figure 1, 2..." and no reference list for the references.
hope can upload the full essay for full view!
1 out of 1 people found this comment useful.