Part I.
In this section of this essay you will see a DNA sequence converted into its RNA equivalent and then converted into an amino acid sequence. Inside DNA and RNA strands, there are four types of bases and these bases can be arranged in any order, and this sequence is what encodes genetic information (Audesirk, 2008, p. 157). The double helix of DNA only has A àT and G àC pairs thus, the following sequence 5àâ TACTTCTTCAAGACT à3àcan be converted to the RNA equivalent of 5àâÂÂAUGAAGAAGUUCUGA à3ÃÂsince the base pairs when converting from DNA to RNA are in A àT, U àA, and G àC pairs, meaning that RNA does not contain deoxyribose, it contains ribose and has a base of uracil instead of thymine as found in DNA. In order to convert this sequence into an amino acid sequence we must use the genetic code which ÃÂtranslates the sequence of bases in nucleic acids into the sequence of amino acids in proteinsà(Audesirk, 2008, p.
 English: Gene expression pattern of the FGFR3 gene...
English: Gene expression pattern of the FGFR3 gene...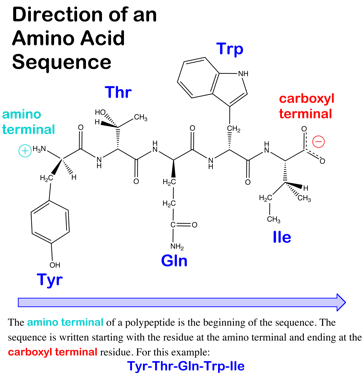 English: direction of an amino acid sequence with ...
English: direction of an amino acid sequence with ...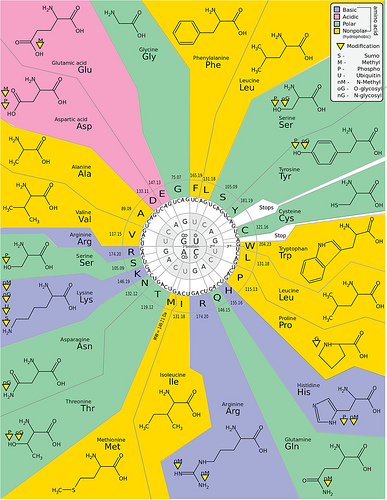 Genetic Code by Kosi Gramatikoff, Seth Miller cour...
Genetic Code by Kosi Gramatikoff, Seth Miller cour...171). Methionine is determined as the start codon in any amino acid sequence and can be identified as mRNA triplet AUG. The stop codons are determined by triplet sets UAG, UAA and/or UGA. So, right away as we look at the RNA equivalent of the DNA strand that we converted, we can tell that in order to find the starting point of the amino acid sequence, we must find the mRNA triplet of AUG, as well as find the stop codon, which in this case is the mRNA triplet UGA. So the first and last codons in this RNA sequence are going to be our start and stopping points. So, the amino acid sequence would read as follows: Methionine (Start), Lysine, Lysine, Phenylalanine,