Cladistics is defined as "a classification scheme based on the historical sequence of divergence events (phylogeny); also used to identify a method of inferring phylogenies based on the presence of sheared derived characters (synapomorphies)" (Freeman, 2001). A paper was found on "cladistic analysis of languages: Indo-European classification based on lexicostatistical data," by examining this article a better understanding of how cladistical experimentation is preformed, can be achieved. In order to understand this, an examination of the goals of the experiment, the materials and methods, and the results obtained from the study must be accomplished. "Many languages are believed to be related in a hierarchical tree-like pattern, and it is therefore possible to apply cladistic methods to infer language trees" (Rexova, 2003).
This study focuses on "the phylogeny of the Indo-European (IE) language family reconstructed by application of the cladistic methodology to the lexicostatistical dataset by Dyen" (Rexova, 2003). This study attempts to apply the "cladistic methodology to the analysis of the basic vocabulary data" (Rexova, 2003).
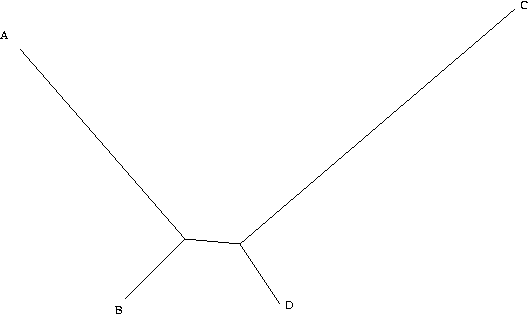 An example of long branch attraction. Branches A &...
An example of long branch attraction. Branches A &...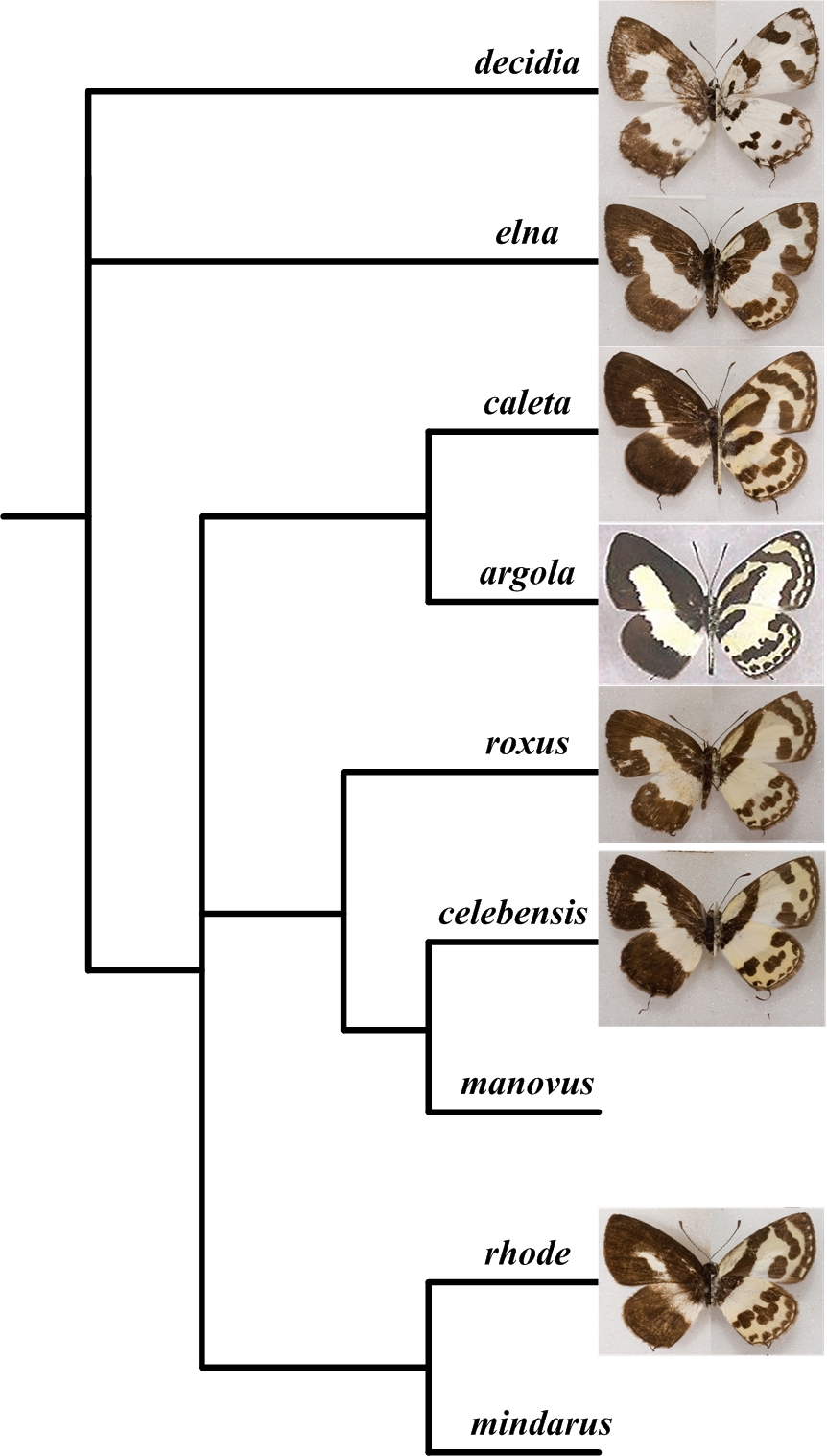 English: Cladistic analysis of Caleta after Hirowa...
English: Cladistic analysis of Caleta after Hirowa...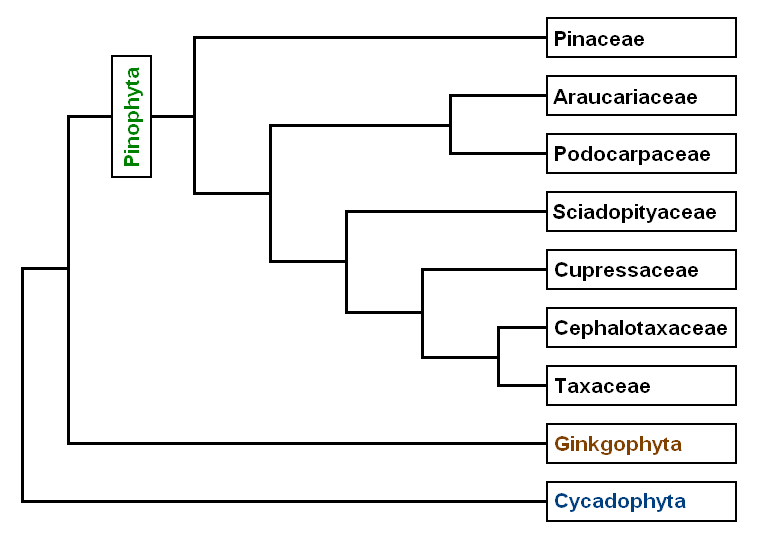 Phylogeny of the Pinophyta based on cladistic anal...
Phylogeny of the Pinophyta based on cladistic anal...They substantiate this approach, by assuming that: "(1) individual languages are the subjects of cultural evolution (the problem of general biological basis of the language can be ignored here) and preserve their continuity throughout long time scales; (2) the evolution of languages is mostly divergent; and (3) the language is transmitted as a whole, and the frequency of borrowing (i.e., horizontal transmission of individual characters) between language is low." (Rexova, 2003). The goal of this study is to "(1) perform a phylogenentic analysis of lexical (basic vocabulary) data using the maximum parsimony approach; (2) evaluate robustness of the trees to different modes of recognition of the primary homologies and to different character-coding strategies; (3) compare the results with earlier analyses of the same dataset carried out by classical lexicostatistical methodology (Dyen et al., 1992);...